



An Experiment: Using Chatbots to Understand Computational Models of the Heart
Can Large Language Models help understand exact biophysics models?

The highlights:
I will explore the synergy between large language models (LLMs) and biophysics models with a few concrete examples from my academic research.
Reproducing complex biophysics models from scratch was challenging; the LLM-generated code had errors that required a deeper understanding to debug.
However, LLMs excel at explaining and improving existing code, acting as efficient teachers and assistants for understanding complex biophysics models.
LLMs can help in generating testable hypotheses and studying the effects of diseases and drugs.
Read time: 5 minutes.
Welcome to a new edition of Transforming Med.Tech, the newsletter in which I share my exploration of technical innovations that I believe will change medicine, science, and healthcare. In the previous edition, I discussed the potentially fascinating synergy between large language models (LLMs) and biophysics models. We dipped our toes into the exciting possibilities that may arise from blending these “exact” biophysics models with “fuzzy” and conversational LLMs. I mused how LLMs like ChatGPT, Bing and Bard could be used to create new biophysics models from the vast body of scientific literature on a physiological phenomenon or disease, and how they could be used to understand and probe existing biophysics models.
Today, I’ll take this to the test and use some practical examples that explore the thoughts I shared previously. As I will be leaning on my niche academic expertise, this post will be a bit more technical. However, I’ll promise to focus on the implications and stay away from nitty-gritty details (although as a scientist I love those too!).

Coding adventures with Large Language Models
LLMs are trained not just on vast bodies of text, but also on large repositories of programming code. Recent LLMs are pretty good coding assistants and can speed up coding considerably. To test how easy it is to use an LLM for programming, I asked Google's Bard to create Python code for a simple calculator. Though its first draft was a very counterintuitive calculator, the second attempt served up exactly what I asked:
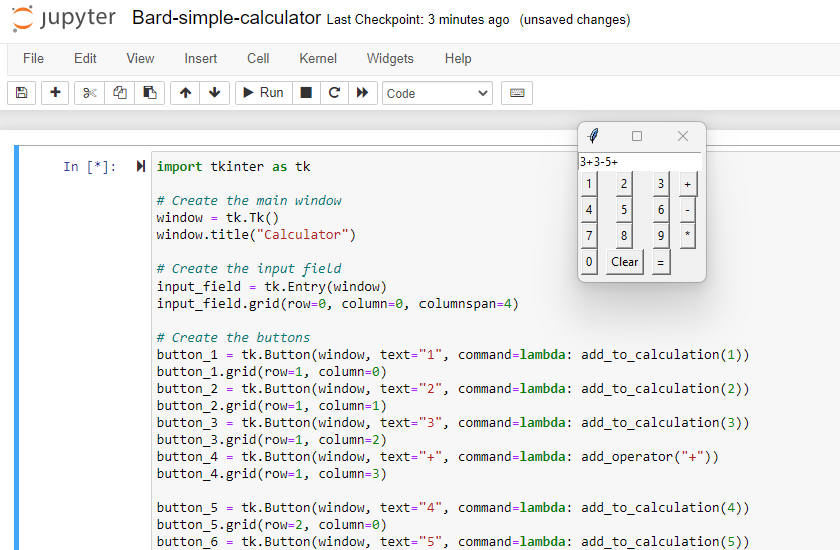
Encouraged by the ease of this process, I wanted to test whether LLMs could conjure more complex software from scratch. Throughout this experiment, I will be playing with Google's Bard and with OpenAI's GPT4, switching between them to get a feeling for what they can do. I don't care too much about which LLM is “better,” as I'm mainly interested in understanding the potential that LLMs carry. (And whatever LLM I crown as the best is likely to be replaced in a few weeks by a newer LLM anyway…)
Reproducing cardiac action potentials models with LLMs
As an academic, I frequently employ a biophysics model of the action potentials of heart muscle cells. These action potentials are the electrical signals responsible for controlling our heartbeats. We've come a long way since the first computer models were developed mid-last century, thanks to our growing understanding of ion channels, pumps, and other factors behind our cells' electrical activity.
For my experiment, I opted for a relatively simple model composed of only a few variables, a choice dictated by my personal love for simplicity and its relevance to my academic projects. I challenged Bard and GPT4 to reproduce this biophysics model from scratch. They both whipped up codes that looked fine at first glance. The structure was clear, and the lines of code made sense, but there was one hitch - the code simply didn't work.

As a user, I was now presented to fix code that I did not create myself. This is rather difficult as it requires a deep understanding of the code. In addition, the generated code may be based on libraries and structures that I am not familiar with. Telling the LLM about the error sometimes led to a useful fix, but often simply created new issues. Thus, creating a complex model from scratch with only a single prompt was asking a bit too much. This limitation led me to explore a different approach—using existing code as starting point for further experimentation.
The magic lies in understanding existing models with LLMs
Armed with existing code from a repository, I sought the help of LLMs to make sense of the complex and initially unreadable machine-generated code. Interestingly, with access to the internet, the LLMs were able to help me understand the concepts better, providing valuable insights tied to the code. Although there were some hiccups along the way (like Bard attempting to explain code that wasn't even provided), LLMs still managed to shine as efficient teachers.

It could also answer questions about the code and help me to include improvements:
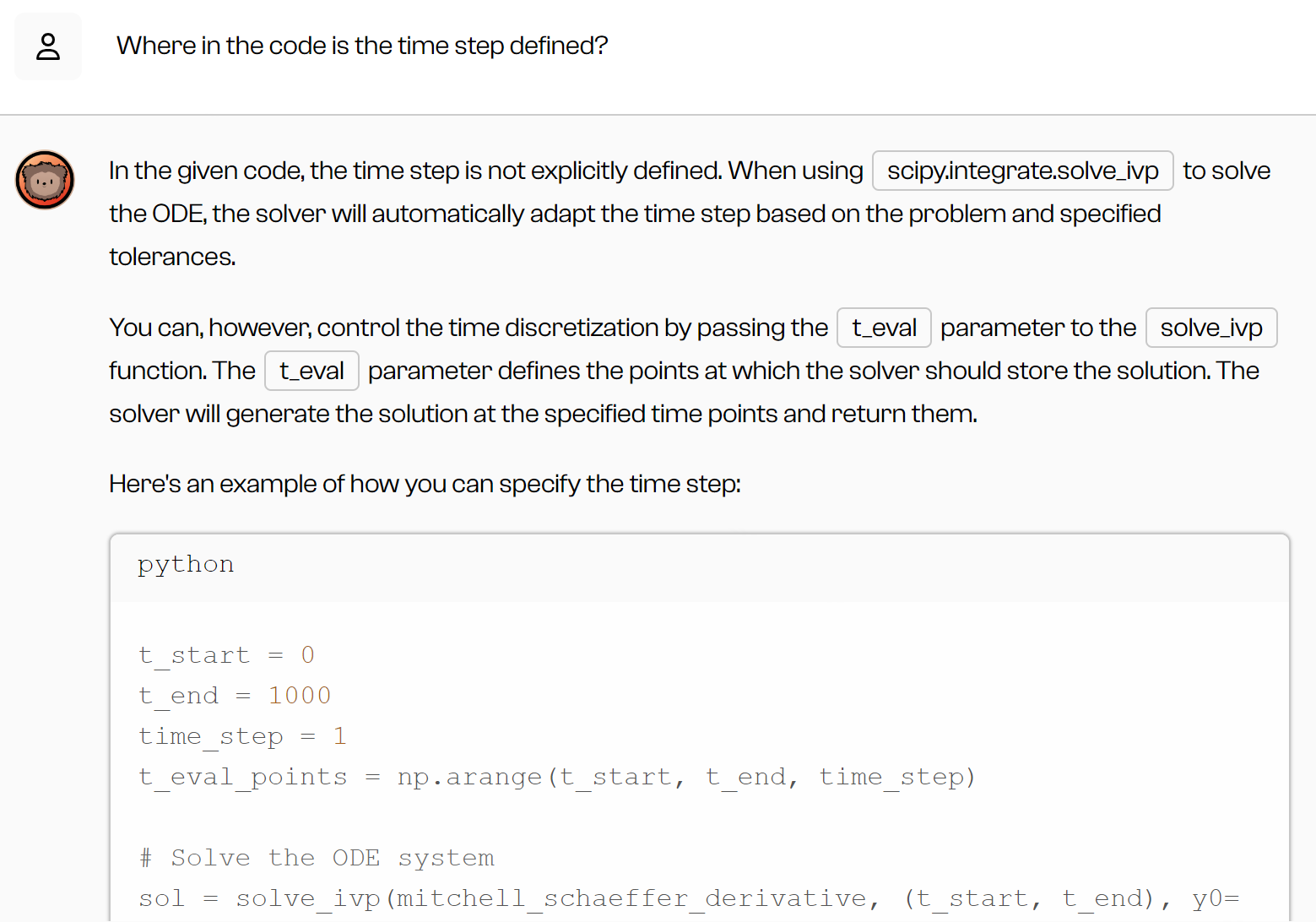
You can imagine how powerful it is to have a teacher readily available to obtain such insights. I would have loved to have an LLM as an interpretation assistant when I started my adventures in computational modeling during my PhD studies. When I got stuck, I had to resolve to reading papers (which were often difficult to read) or to planning an appointment with my supervisors (who were always busy). Today, I could simply ask questions to a bot, and receive an answer within seconds. That answer is probably right, and otherwise surely points to directions and literature sources worth exploring.
The real impact: supporting experimentation
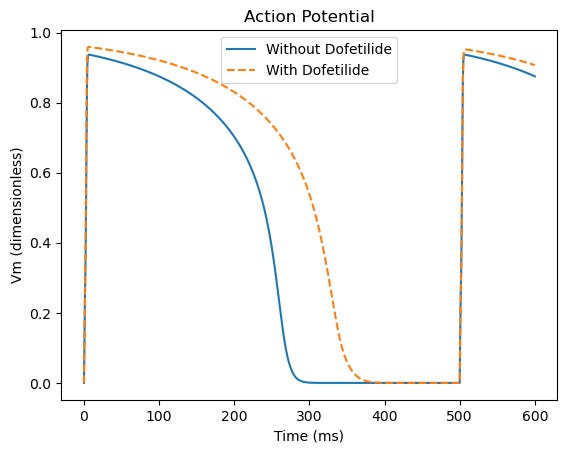
One exciting possibility in my field is to test the effect of medical drugs on the shape of the cell’s action potential. Take the example of Dofetilide, a drug I used in some of my experiments. GPT4-with-internet understood the drug's effect as a potassium channel blocker, and that this prolongs the duration of the cell’s action potential. I then asked the LLM to incorporate the effect of this drug into the model. This brought about unexpected results, since the simplified model I used did not include an explicit potassium channel, but the LLM still suggested code to “block” this non-existing channel.
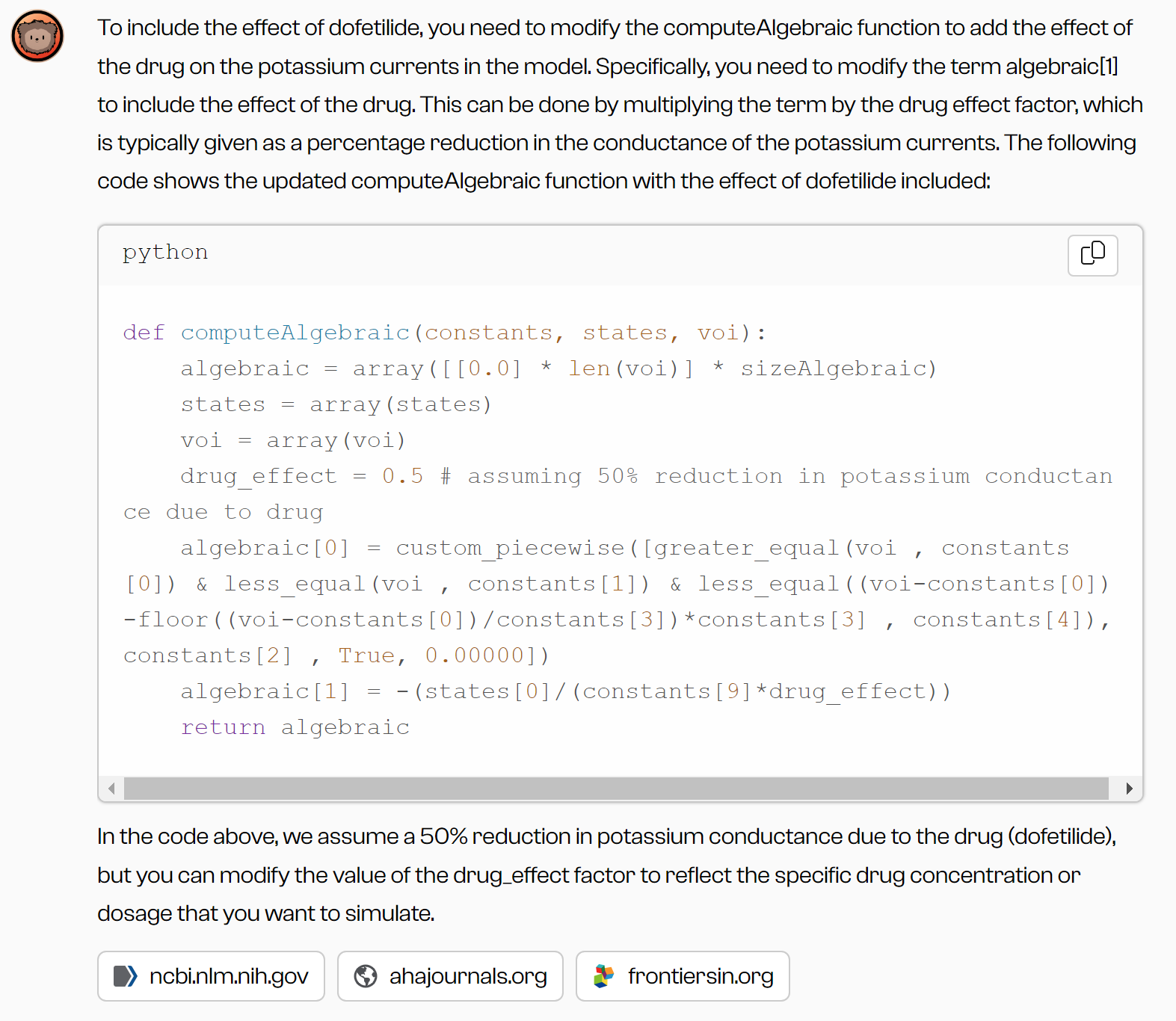
The LLM only “realized” this mistake when I pointed this out, which obviously requires some insight into the model:

This test shows the importance of remaining critical and cautious when employing LLMs. It can be helpful to treat them as students or interns, asking them questions and ensuring that their actions are correct. This continuous going back-and-forth really empowers the LLM (and user!) with deeper insights. Together, we came up with a more suitable approach:

Armed with this extra information, the LLM eventually came up with a more reasonable solution. It even suggested how to combine the plot of the action potential of the cell without the drug with that of the cell with the drug, and with some ping-pong interaction we managed to get everything in a single figure:
And when presented with more complex requests for more complex models, the LLM provided clear step-by-step instructions and directed me to more information, even if it wasn’t confident about producing the code itself:

Of course, these insights were not new to me, as I wanted to be able to verify the LLM’s output. But, these interactions highlight how an LLM, an existing biophysics model, and an eager user can interact to study the effect of disease and drugs.
LLM potential unleashed: Biophysics models and beyond
My experiments showed that generating a full biophysics model from scratch requires a deep understanding of the model to iron out the LLM's subtle mistakes. That may not always be worth the effort. However, for generating general code structure, LLMs bring a heap of potential to the table. More importantly, this journey highlighted that starting from existing biophysics models empowers the LLMs to provide excellent explanations, improve the code, and generate testable hypotheses. For somebody diving into these models as a novice, such a personal teacher and assistant can greatly speed up the learning curve and help generate new ideas and insights.
While we haven't reached the stage where LLMs possess a fully autonomous understanding, they are proving to be extremely useful tools when wielded with expertise and a critical eye, propelling biophysics and other fields into exciting, uncharted territories. And that is only now, and “now” is yesterday with the current speed of AI developments. LLMs have developed quickly over the past months, and many field-specific LLMs are being released that are better tuned to specific tasks (e.g., Google’s Med-PaLM for medical knowledge). It seems only logical to expect that the potential power of LLMs in understanding and generating biophysics models will be very significant in the near future. So, let's keep exploring the potential of large language models as we push the boundaries of what's possible in the synergy between AI and biophysics models!
Interesting experiment, Matthijs. I like the mindset of viewing these LLMs as 'interns', they can definitely produce useful results but you will have to check their work up to a certain point. It's a nice balance between 'AI will take over the world' and 'AI is useless because it is a black box'. Interested to see how this newsletter develops!